OpenAI最近似乎搞了个大新闻,随手一搜,”最大模型”、”15亿参数”、”无需领域数据”等等跃然在目。当然现在是标题党的年代,为了吸引眼球,外行媒体的夸张手法也能理解。当然最大的争议还是他们在官网上解释为什么只提供小模型的理由:为了防止大模型用于生成欺诈和有歧视性的文章,我们只发布小规模的模型(Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code)。这个当然引起了轩然大波,使得很多人在Reddit上吐槽。听这语气,人工智能已经实现了,为了保护人类,他们不能把这个恶魔放出来。实际情况怎么样呢?别听专家的,最好还是我们自己读读论文跑跑代码吧。
目录
背景简介
BERT的缺陷
语言模型
Children’s Book
LAMBADA
Winograd Schema Challenge
Reading Comprehension
Summarization
机器翻译
Question Answering
大翻盘
代码
背景简介
2018年深度学习在NLP领域取得了比较大的突破,最大的新闻当属Google的BERT模型横扫各大比赛的排行榜。作者认为,深度学习在NLP领域比较重点的三大突破为:Word Embedding、RNN/LSTM/GRU+Seq2Seq+Attention+Self-Attention机制和Contextual Word Embedding(Universal Sentence Embedding)。
Word Embedding解决了传统机器学习方法的特征稀疏问题,它通过把一个词映射到一个低维稠密的语义空间,从而使得相似的词可以共享上下文信息,从而提升泛化能力。而且通过无监督的训练可以获得高质量的词向量(比如Word2vec和Glove等方法),从而把这些语义知识迁移到数据较少的具体任务上。但是Word Embedding学到的是一个词的所有语义,比如bank可以是”银行”也可以是”水边。如果一定要用一个固定的向量来编码其语义,那么我们只能把这两个词的语义都编码进去,但是实际一个句子中只有一个语义是合理的,这显然是有问题的。
这时我们可以通过RNN/LSTM/GRU来编码上下文的语义,这样它能学到如果周围是money,那么bank更可能是”银行”的语义。最原始的RNN由于梯度消失和梯度爆炸等问题很难训练,后来引入了LSTM和GRU等模型来解决这个问题。最早的RNN只能用于分类、回归和序列标注等任务,通过引入两个RNN构成的Seq2Seq模型可以解决序列的变换问题。比如机器翻译、摘要、问答和对话系统都可以使用这个模型。尤其机器翻译这个任务的训练数据比较大,使用深度学习的方法的效果已经超过传统的机器学习方法,而且模型结构更加简单。到了2017年,Google提出了Transformer模型,引入了Self-Attention。Self-Attention的初衷是为了用Attention替代LSTM,从而可以更好的并行(因为LSTM的时序依赖特效很难并行),从而可以处理更大规模的语料。Transformer出来之后被广泛的用于以前被RNN/LSTM/GRU霸占的地盘,Google更是在Transformer的论文里使用”Attention is all you need”这样霸气的标题。现在Transformer已经成为Encoder/Decoder的霸主。
虽然RNN可以学到上下文的信息,但是这些上下文的语义是需要通过特定任务的标注数据使用来有监督的学习。很多任务的训练数据非常少并且获取成本很高,因此在实际任务中RNN很难学到复杂的语义关系。当然通过Multi-Task Learning,我们可以利用其它相关任务的数据。比如我们要做文本分类,我们可以利用机器翻译的训练数据,通过同时优化两个(多个)目标,让模型同时学到两个任务上的语义信息,因为这两个任务肯定是共享很多基础语义信息的,所以它的效果要比单个任务好。但即使这样,标注的数据量还是非常有限的。
因此2018年的研究热点就变成了怎么利用无监督的数据学习Contextual Word Embedding(也叫做Universal Sentence Embedding),也就是通过无监督的方法,让模型能够学到一个词在不同上下文的不同语义表示方法。当然这个想法很早就有了,比如2015年的Skip Thought Vector,但是它只使用了BookCorpus,这只有一万多本书,七千多万个句子,因此效果并没有太明显的提升。
在BERT之前比较大的进展是ELMo、ULMFiT和OpenAI GPT。尤其是OpenAI GPT,它在BERT出现之前已经横扫过各大排行榜一次了,当然Google的BERT又横扫了一次,并且PR效果更加明显。所以OpenAI看风头都被Google强劲,自然有些羡慕嫉妒恨,也就有了今天我们要讨论的OpenAI GPT-2。
UMLFiT比较复杂,而且效果也不是特别好,我们暂且不提。ELMo和OpenAI GPT的思想其实非常非常简单,就是用海量的无标注数据学习语言模型,在学习语言模型的过程中自然而然的就学到了上下文的语义关系。它们俩都是使用Transformer来学习语言模型,但是在进行下游任务处理的时候就有所不同,ELMo是把它当成特征。拿分类任务来说,输入一个句子,用ELMo把它扫一次,这样就可以得到每个词的表示,这个表示是考虑上下文的,因此”He deposited his money in this bank”和”His soldiers were arrayed along the river bank”中的两个bank的向量是不同的。下游任务用这些向量来做分类,它会增加一些网络层,但是ELMo语言模型的参数是固定的。而OpenAI GPT不同,它直接用特定任务来Fine-Tuning Transformer的参数。因为用特定任务的数据来调整Transformer的参数,这样它更可能学习到与这个任务特定的上下文语义关系,因此效果也更好。
而BERT和OpenAI GPT的方法类似,也是Fine-Tuning的思路,但是它解决了OpenAI GPT(包括ELMo)单向信息流的问题,同时它的模型和语料库也更大。依赖Google强大的计算能力和工程能力,BERT横扫了OpenAI GPT,在后者霸主宝座屁股还没坐热的时候就把它赶下台。成王败寇,再加上Google的PR能力,很少还有人记得OpenAI GPT的贡献了。要说BERT的学术贡献,最多是利用了Mask LM(这个模型在上世纪就存在了)和Predicting Next Sentence这个Multi-task Learning而已,其余的方法都是完全follow OpenAI GPT的。因此OpenAI心情郁闷也就可以理解了,这次搞出个GPT-2也是想出来露个脸,刷一下存在感。
更多技术细节,有兴趣的读者可以参考详解谷歌最强NLP模型BERT或者参与作者的BERT课程。地址:http://fancyerii.github.io/2019/03/05/bert-prerequisites/
BERT的缺陷
如果你是OpenAI GPT的科学家,你会怎么办呢?当然如果能提出一个更加突破性的模型,然后在各大比赛上横扫BERT,这自然是最理想的。但是学术研究又不能像媒体宣传的那样天天突破(作者订阅的各种公众号倒是每天都能看到突破,因此经常被震惊),要拼资源和算力那显然拼不过Google。其实除了OpenAI,其它公司也想搞点新闻,比如Microsoft最近搞了个MT-DNN,据说效果要比BERT好(一点),但是由于好的有限,而且有没有源代码甚至模型,谁知道是不是用tricky的方法过拟合这些数据集呢?
我们回到OpenAI,显然短期类无法超过BERT,Google开源的BERT模型横扫了其它更多榜单,仿佛挑衅般的对其他对手说:不服你跑个分啊。被当面打脸,显然很郁闷。那怎么办呢?OpenAI的科学家突然找到了BERT模型的一个弱点——它不是”正常的”语言模型,因此不能生成句子。BERT的Mask LM只能用来做完形填空题,也就是用手遮住一个句子的某个单词,然后让它猜哪个词更可能,但是普通的语言模型是可以生成句子的。抓住这个点之后,OpenAI大作文章。它使用Common Crawl的8百万文章(共40GB,不知道是否压缩过)训练了一个15亿(1542M)参数的”最大模型”,不过参数虽然很多,但是训练数据确实有点少。作者训练个中文词向量还得搞个几千万的百科文章,Google的数据那得用TB来做单位吧。因此作者在文中强调模型是underfit的(All models still underfit Web-Text and held-out perplexity has as of yet improved givenmore training time.),参数多,数据少,那自然不能训练太久,否则过拟合后效果更差(但是生成句子过拟合无所谓,直接把莎士比亚全集的句子背出来肯定能震惊很多人)。训练了这个模型用来刷榜?我猜测作者尝试过,结果呢?那自然就不用说了,否则我们看到的就不是现在的这个新闻了。
不过没关系,他们的目标是BERT的软肋——不能生成句子(段落和篇章当然就更不行了)。我们来看看论文的实验是怎么设计的:
语言模型
BERT不是普通的语言模型吧,好,那咱们来PK一下(你是零分啊)。但是用Transformer去跑语言模型这样的灌水文章别人早发过了,没啥意思。因此要搞出一个Zero-shot的概念:你们在一个很小的语料库训练一个语言模型然后大家比赛,俺不这么跟你玩。俺用很大的语料训练一个模型,然后不用你的数据,效果还能超过你们在小数据上的效果。
当然这个概念还是不错的,结果如下图所示。
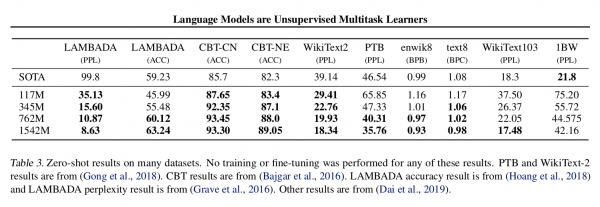
图:不同数据集上语言模型的PPL,越小越好
我们看到,除了最后一个1BW的很大的语料库,OpenAI都超过了它们。其实这也说明了,如果有很多的领域数据,还是领域数据好使,这在机器翻译系统里也得到了验证。如果训练数据较少,我们通常使用预训练的词向量作为模型词向量的初始值。如果训练数据非常少,我们通常固定预训练的词向量;如果训练数据还可以,那么就Fine-Tuning一下。如果训练数据很多,比如在机器翻译任务里,预训练的词向量和随机初始化的效果没什么区别(开始的时候好一点,因为比较是相对较好的初始值)。
Children’s Book
类似于完型填空,其实BERT是可以搞的。但是NLP的比赛那么多,Google总不能都做完吧。国内很多AI公司天天发PR稿:我们又获得了一个世界第一。其实很多外行的读者并不知道这个比赛只有5个参数选手,可能其中2个还是某个在校学生挤出周末打游戏的时间去做的。
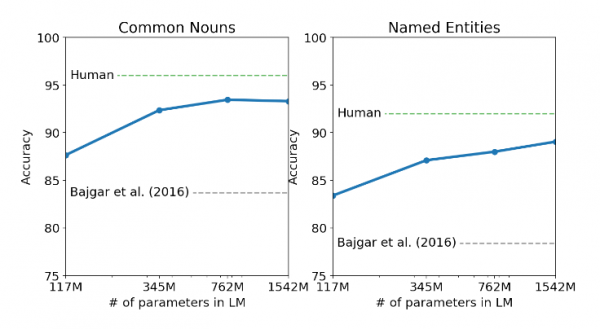
图:Children’s Book任务
效果似乎还不错,离人类的水平相差不远。
LAMBADA
PPL从99.8降到8.6,测试的准确率从19%提高到52.66%。作者不了解这个比赛,不做点评。
Winograd Schema Challenge
63%到70.7%,似乎还不错。作者也不了解这个比赛,不做点评。
Reading Comprehension
这是最近很火的比赛类型,有很多数据集,这里使用的是CoQA,BERT的baseline是89的F1得分(越大越好),GPT-2的得分是55。这似乎差得太远啊,但是作者有高大上的解释:BERT是用来监督数据的,俺们不用训练数据。有点像考试不及格的学渣对学霸说,虽然你得了89分,但是你天天熬夜背题,俺天天翘课也差点及格了,说明俺比你有天赋。学霸说:那你也天天熬夜背题啊,看看能不能跑分跑过我?学渣说:俺们是搞素质教育的,不搞题海战术。
Summarization
摘要任务,分越高越好,成绩单如下:
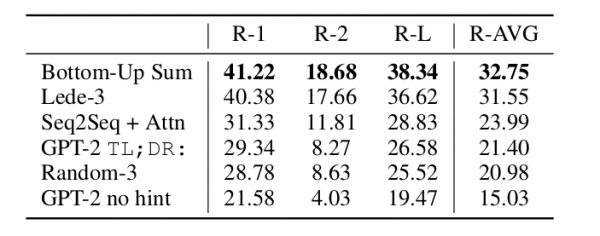
图:Children’s Book任务
机器翻译
SOTA的BLEU分(越高越好)33.5,俺不学习也得了11.5。
Question Answering
无监督的效果惨不忍睹。
大翻盘
这是最终大杀器,咱们来PK生成文章了。论文附录挑选了许多生成的”故事”,作者英语比较差,看不出好坏来。学术界最近对产生式(Generative)模型非常感兴趣,尤其是在图像和视觉领域。不过作者对此并不感兴趣,作者是实用主义者,生成花里胡哨的东西并不能解决实际的问题。大家上网随便一搜,都能找到各种作诗机器人、对联机器人或者生成某些名人风格的文字。看起来格律严谨对仗工整,其实都是毫无意义。当然,也不是说生成的模型完全无用,比如Gmail用模型自动生成邮件的回复,作者试了一下还不错。不管怎么说,OpenAI是扳回一城了,因此也就有了铺天盖地的新闻出来。
代码
因为没有中文模型,只能跑英文,所以作者这三脚猫的英语水平还是藏拙的好,就不做点评了。读者可以自己试试。
git clone https://github.com/openai/gpt-2.git && cd gpt-2
需要安装Tensorflow 1.12.0(作者试了1.11也是可以的,因为BERT的官方实现要求1.11+):
pip3 install tensorflow==1.12.0
安装其它依赖:
pip3 install -r requirements.txt
下载模型:
python3 download_model.py 117M
因为模型放在storage.googleapis.com,所以需要科学上网,可以这样修改代码,请把”127.0.0.1:1080”改成你自己的代理:
$ git diffdiff --git a/download_model.py b/download_model.pyindex 2a38294..83d6fb8 100644--- a/download_model.py+++ b/download_model.py@@ -15,7 +15,11 @@ if not os.path.exists(subdir): for filename in ['checkpoint','encoder.json','hparams.json','model.ckpt.data-00000-of-00001', 'model.ckpt.index', 'model.ckpt.meta', 'vocab.bpe']: - r = requests.get("https://storage.googleapis.com/gpt-2/" + subdir + "/" + filename, stream=True)+ proxies = {+ 'http': 'http://127.0.0.1:1080',+ 'https': 'http://127.0.0.1:1080',+ }+ r = requests.get("https://storage.googleapis.com/gpt-2/" + subdir + "/" + filename, stream=True, proxies=proxies) with open(os.path.join(subdir, filename), 'wb') as f:
使用前需要设置编码:
export PYTHONIOENCODING=UTF-8
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!