本文大纲:
1、爬虫是什么?反爬虫又是什么?
2、爬虫有哪些分类?
3、爬中流程与搜索引擎工作流程
4、http/https协议与状态码
5、robots协议
爬虫是什么?反爬虫又是什么?
这里的爬虫不是我们生活中的爬虫,如蜘蛛。这里的爬虫更多指的是网络爬虫,即我们叫它网页蜘蛛或网络机器人。当然,在SEO里,叫网页蜘蛛更多。
网络爬虫,是一种按照一定规则,自动地抓取互联网上的信息的一种程序。他有一个英文名叫spider,比如百度网页蜘蛛就叫baiduspider,那搜狗的就叫Sogou spider。
这也是我们SEO人员做网站优化排名会听说的一个词。网站为啥没收录呢?原来蜘蛛没来抓取!如何看这个爬虫蜘蛛朋友来没来呢,让技术把网站日志下载给我们,我们就可以判断了,你说算不算好朋友?
百度爬虫是什么?Baiduspider是啥?
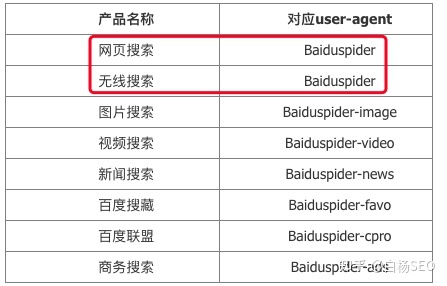
Baiduspider是百度搜索引擎的一个自动程序,它的作用是访问互联网上的网页,建立索引数据库,使用户能在百度搜索引擎中搜索到网站上的网页。百度还有哪些蜘蛛呢?如下图。最多是圈中这个,记得哈~
图片
反爬虫是什么?
我们以门户网站举例,企业网站也同理哈。门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取,这就叫反爬虫。
当然,其实还有反反爬虫,即爬虫程序通过相应的策略和技术手段,破解了门户网站的反爬虫手段,从而爬取到相应的数据,这就叫反反爬虫。
再白话举例:你要来采集我的内容(爬虫),我不给你采并且我做防采集(反爬虫)。你呢,又搞了更高技术把我防采集攻破了采集(反反爬虫),这样理解了吧?
爬虫有哪些分类?
爬虫总共就分两类:通用爬虫与聚焦爬虫。
通用爬虫:简单说就是尽可能的把网上的所有的网页下载下来,放到服务器里再对这些网页做相关处理,最后给用户搜索用,通常指的搜索引擎爬虫。比如:谷歌爬虫、百度爬虫、搜狗爬虫、360爬虫等。
聚焦爬虫:它是根据指定的需求抓取网络上指定网站的数据。比如:获取知乎问答上的某一问题的浏览量和回答人数,而不是获取整个页面中所有数据。它也可以理解叫特定爬虫。
上面提到的反爬虫与反反爬虫,基本上都是在反这种聚焦爬虫哈,你也可以理解为爬虫攻防战哈哈哈。
爬中流程与搜索引擎工作流程
爬虫一般工作流程:确定某个URL——发送请求——响应内容——提取数据——保存数据。
搜索引擎蜘蛛工作流程:爬取网页——存储数据——数据预处理——提供用户搜索网页排名。
是不是感觉难理解?发送请求是什么,响应内容又是什么?这个往下看HTTP协议与状态看完你就懂了。
关于搜索引擎数据预处理在处理什么,怎么理解?看公众号白杨SEO两年前写过这篇《白杨SEO:大白话告诉你理解搜索引擎工作原理的意义和运用》,看完你就懂了。
http/https协议与状态码
HTTP协议是指Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网 WWW(World Wide Web缩写)服务器传输超文本到本地浏览器的传送协议。默认端口号:80。
而HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议指的是HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。默认端口号:443。
你是不是理解不了这个HTTP到底什么东东?简单白话来说这个就是用来传输和接收页面的,保证你的电脑能快速传输文本文档并且让你看到哈。
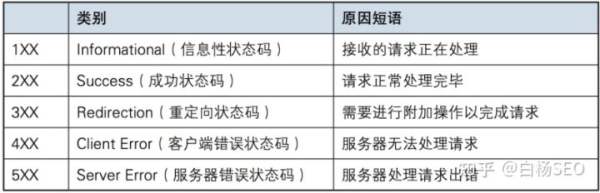
至于HTTP的请求头,响应头,都是各种代码,白杨SEO就不在这里写了,如果你要真的想了解,自己去搜索,这里只讲一下我们SEO中会看到的HTTP请求响应状态码,一般状态码如下:
图片
上面只要是2或者3开头都是好的,比如查白杨SEO博客的:
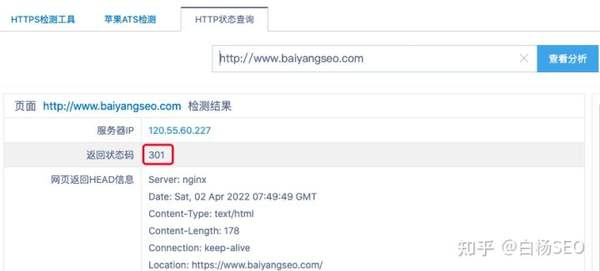
图片
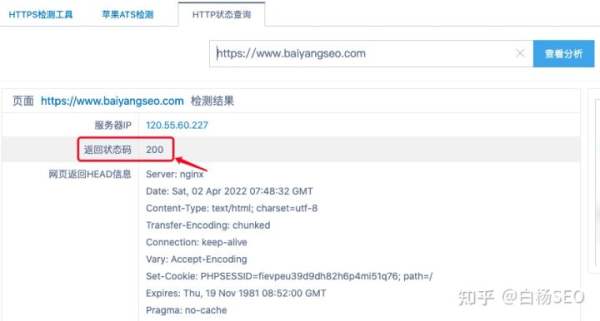
图片
输入http://www.baiyangseo.com返回是301,而输入https://www.baiyangseo.com 返回的是200正常的你知道为什么吗?
其实,这在SEO里来说,是因为两个不同URL内容是一模一样,为了让搜索引擎避免认为作弊,所以做了301永久重定向。简单理解,你用不带s的HTTP那个域名打开就是这个带的了哈。
关于这个状态码,如果你想学习了解更深入一点,同样可以白杨SEO公众号上这篇:《白杨SEO:SEO入门学习之搜索引擎蜘蛛与网站HTTP状态码》
robots协议
最后,来到针对搜索引擎网页蜘蛛robots协议了。这个如果你是学SEO的,肯定要学的。
robots协议是什么?简单理解就是网站通过Robots协议告诉搜索引擎,网站上哪些页面可以抓取,那些页面不能抓取!但是,它仅仅是互联网中的一种约定而已。所以有些人说我明明禁止XXX蜘蛛还是被抓取了哈哈哈。
它长啥样?到底有什么用?
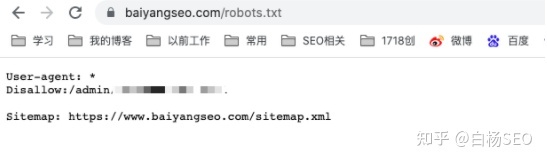
图片
长啥样,如上图,作用就是上面说的,在SEO里就是告诉蜘蛛来爬我这里,一般每个站都会做这个,因为蜘蛛首先要爬取一个页面这个地方是最先爬取的,也会反复爬取。
不要问我为啥要给蜘蛛爬取,你做一个网站目的是啥,不就是要让蜘蛛爬取然后用户搜索的时候看到你带来流量吗?当然,你说我做网站只是用来存储我自己看除外哈哈哈。
作者简介:
白杨SEO,专注SEO研究十年,SEO、流量实战派,对互联网精准流量有深入研究。个人微信:baiyang2047
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!